
작성일자 : 2023-11-08
Ver 0.1.1
1. Intro

ORACLE에서 집계함수와 GROUP BY를 통해서 그룹 내에서 집계를 할 수 있다.
예를 들면 그룹별로 MAX 또는 MIN 함수를 통해 최소, 최대 값을 쉽게 구할 수 있다.
그렇지만, MIN / MAX에 해당하는 행의 값 중에서 특정 컬럼의 값을 같이 표시하기 위해서는 어떻게 해야할까?
이런 경우 서브 쿼리를 사용하는 방법이 많이 사용되지만, KEEP 키워드를 사용하면 한 번의 쿼리문으로 MIN / MAX에 해당하는 행의 값들을 쉽게 가져올 수 있다.
2. 사용법
집계함수(집계 컬럼) KEEP (DENSE_RANK LAST / FIRST ORDER BY 정렬 컬럼1, 정렬 컬럼2 ,... ) - 마지막 / 첫번째 순위 값
KEEP 키워드는 GROUP BY 절 또는 OVER 절과 함께 사용해야 한다.

예제를 통해 함수에 대해서 살펴보도록 하자.
시나리오는 EMP 테이블에서 직군별로 직원수와 급여 평균, 그리고 최저, 최고 급여 값 그리고 그 최저, 최고 급여를 어느 직원이 받고 있는지 조회 하고자 한다.
SELECT JOB
, COUNT(EMPNO) AS CNT_EMP -- JOB별 직원 수
, ROUND(AVG(SAL),1) AS AVG_SAL -- JOB별 평균 급여 확인
, MIN(ENAME) KEEP(DENSE_RANK FIRST ORDER BY SAL) AS MIN_SAL_EMP -- JOB별 최저 급여 직원 확인
, MIN(SAL) AS MIN_SAL
, MAX(ENAME) KEEP(DENSE_RANK LAST ORDER BY SAL) AS MAX_SAL_EMP -- JOB별 최고 급여 직원 확인
, MAX(SAL) AS MAX_SAL
FROM SCOTT.EMP
GROUP BY job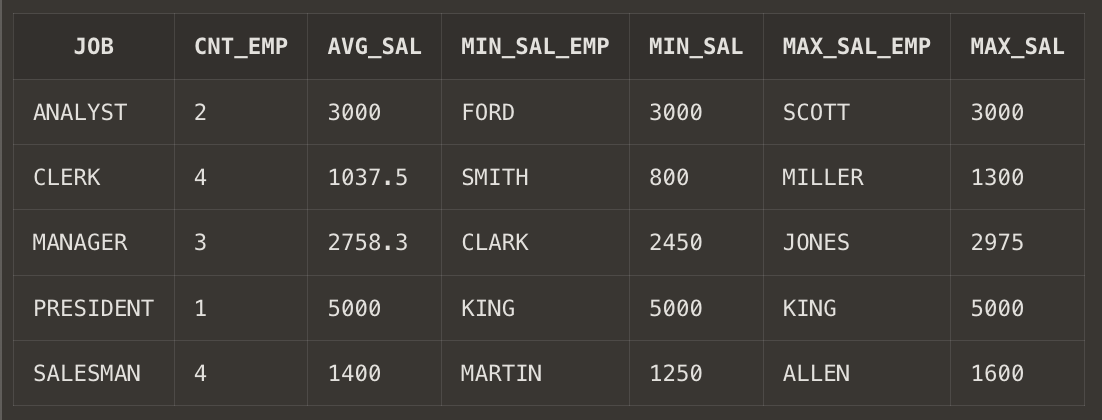
Intro에서 언급한 대로 직군별 최고, 최저 급여는 MAX(SAL), MIN(SAL)을 통해 쉽게 구할 수 있다.
하지만 직원의 이름을 가져오기 위해서는 KEEP 함수 사용이 필요하고, KEEP 함수를 사용하지 않고서는 한 번의 쿼리문으로 구현하기가 쉽지 않다.
SELECT ENAME
,JOB
,SAL
,DENSE_RANK() OVER (PARTITION BY JOB ORDER BY SAL) AS RNK
FROM SCOTT.EMP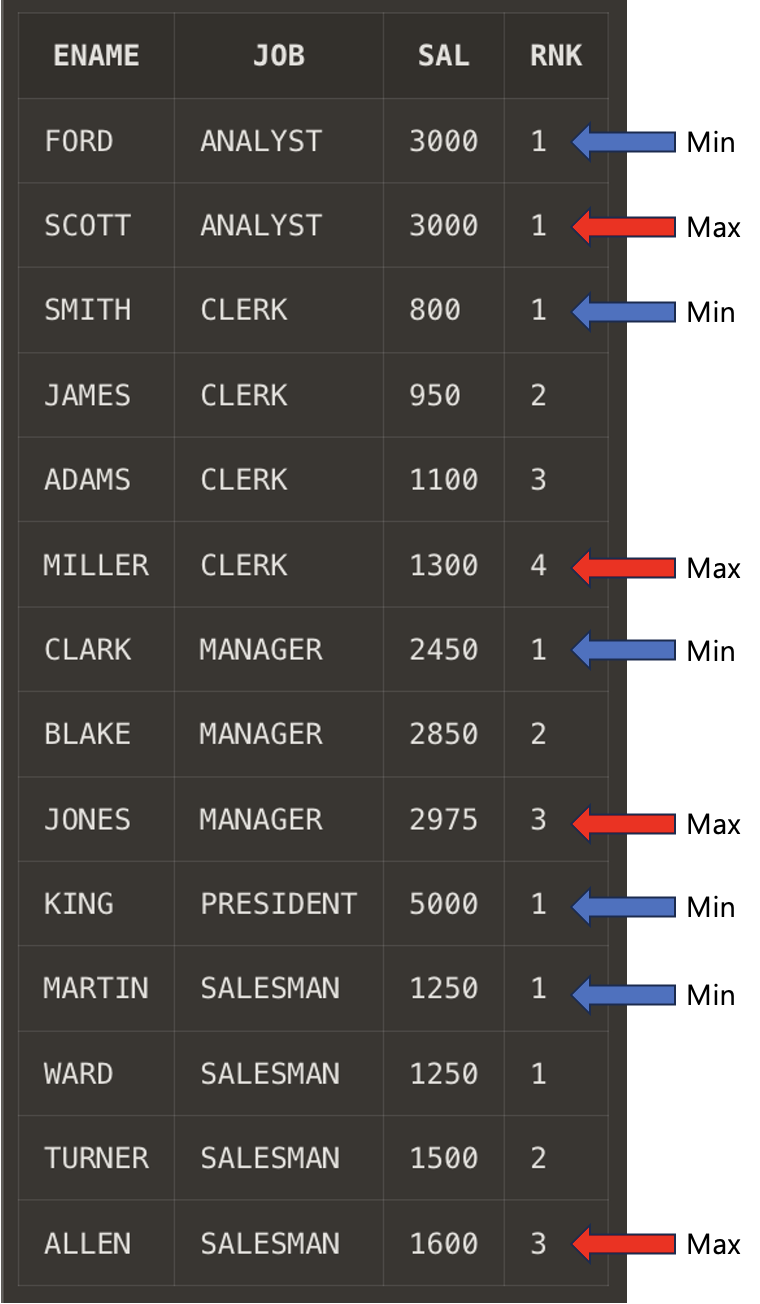
JOB이 ANALYST 인 경우 첫 순위의 행이 같은 값으로 2개이지만, 정렬에 의해 FORD가 MIN값, SCOTT이 MAX 값으로 출력된다.
FIRST : MIN(ename) → 'FORD'
LAST : MAX(ename) → 'SCOTT'
이 처럼 순위가 중복되는 경우 의도하는 대로 또는 정확하지 않는 값이 표시될 수 있기에, 의도하는 대로 정렬 조건을 세분화 또는 추가하여 순위가 겹치지 않게 할 수도 있을 것이다.
3. Wrap up
KEEP 함수를 통해 집계 함수의 첫번째, 마지막 값의 다른 컬럼 값을 조회할 수 있다.
예제에서는 MIN, MAX 집계를 통해 살펴보았지만, 상황에 따라 다른 집계 함수(SUM, AVG , ... 등)을 통해 쿼리를 작성하면 될 것이다.
참고 사이트 : https://gent.tistory.com/475